

Sign Up for the Newsletter
The most up-to-date news and insights into the latest emerging technologies ... delivered right to your inbox!
Study attempts to tackle the problem of decentralized collaboration
August 3, 2022
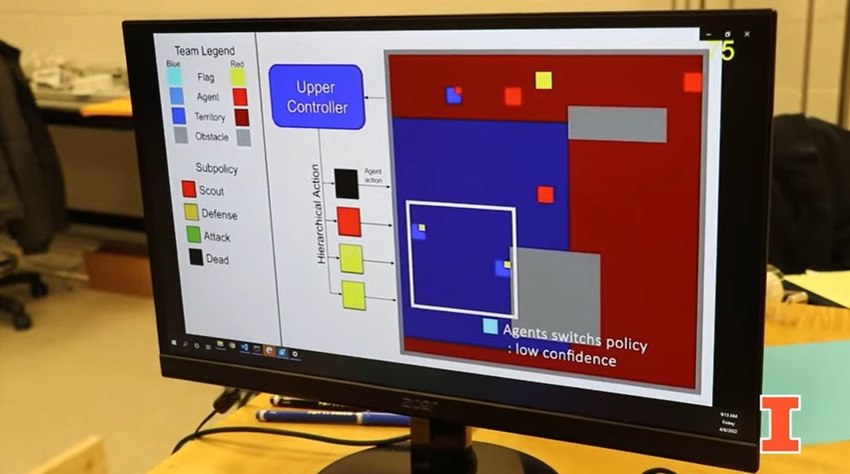
A group of researchers at the University of Illinois Urbana-Champaign used artificial intelligence to “train” teams of robots or drones to work together without the benefit of communicating with one another.
This kind of decentralized, AI teamwork is difficult to accomplish because it’s not clear to individual agents what they should do to help a group accomplish a larger goal. The researchers worked to “disentangle” an individual’s impact on a group task to ensure coordination when training decentralized agents using multi-agent reinforcement learning (MARL), a type of machine learning.
“With team goals, it’s hard to know who contributed to the win,��” said Huy Tran, an aerospace engineer at the university and one of the researchers. “We developed a machine-learning technique that allows us to identify when an individual agent contributes to the global team objective. If you look at it in terms of sports, one soccer player may score, but we also want to know about actions by other teammates that led to the goal, like assists. It’s hard to understand these delayed effects.”
The science applies to many real-life situations, including military surveillance, robots working together in a warehouse, traffic-signal control, autonomous vehicles or controlling an electric power grid, the team says. Most existing applications use a centralized structure to direct agents, an approach that struggles when deployed in large, unpredictable environments with limited communication.
“It’s easier when agents can talk to each other,” Tran said. “But we wanted to do this in a way that’s decentralized, meaning that they don’t talk to each other. We also focused on situations where it’s not obvious what the different roles or jobs for the agents should be.”
Specifically, the engineers used MARL to teach the agents to play simulated games, like capture the flag and Starcraft, a popular computer game. The algorithms include a utility function that tells an agent when it is doing something useful or good for the team and one that identifies when an agent is doing something that doesn’t contribute to the goal.
The team’s study, “Disentangling Successor Features for Coordination in Multi-agent Reinforcement Learning,” was published in the Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems in May. Tran and Girish Chowdhary advised students Seung Hyun Kim and Neale Van Stralen on the project.
You May Also Like
.png?width=700&auto=webp&quality=80&disable=upscale)


.png?width=300&auto=webp&quality=80&disable=upscale)
.png?width=300&auto=webp&quality=80&disable=upscale)
.png?width=300&auto=webp&quality=80&disable=upscale)
